FlexLLM: Token-Level Co-Serving of LLM Inference
and Finetuning with SLO Guarantees
 Carnegie Mellon University
Carnegie Mellon University
 Purdue University
Purdue University
 Anthropic PBC
Anthropic PBC
 Stanford University
Stanford University
 Mistral AI
Mistral AI
 Amazon Web Services
Amazon Web Services
Abstract
Finetuning large language models (LLMs) is essential for task adaptation, yet today's serving stacks isolate inference and finetuning on separate GPU clusters—wasting resources and under-utilizing hardware. We introduce FlexLLM, the first system to co-serve LLM inference and PEFT-based finetuning on shared GPUs by fusing computation at the token level.
FlexLLM's static compilation optimizations—dependent parallelization and graph pruning—significantly shrink activation memory, leading to end-to-end GPU memory savings by up to 80%. At runtime, a novel token-level finetuning mechanism paired with a hybrid token scheduler dynamically interleaves inference and training tokens within each co-serving iteration, meeting strict latency SLOs while maximizing utilization.
In end-to-end benchmarks on LLaMA-3.1-8B, Qwen-2.5-14B, and Qwen-2.5-32B, FlexLLM maintains inference SLO compliance at up to 20 req/s, and improves finetuning throughput by 1.9-4.8× under heavy inference workloads and 2.5-6.8× under light loads, preserving over 76% of peak finetuning progress even at peak demand.
Method
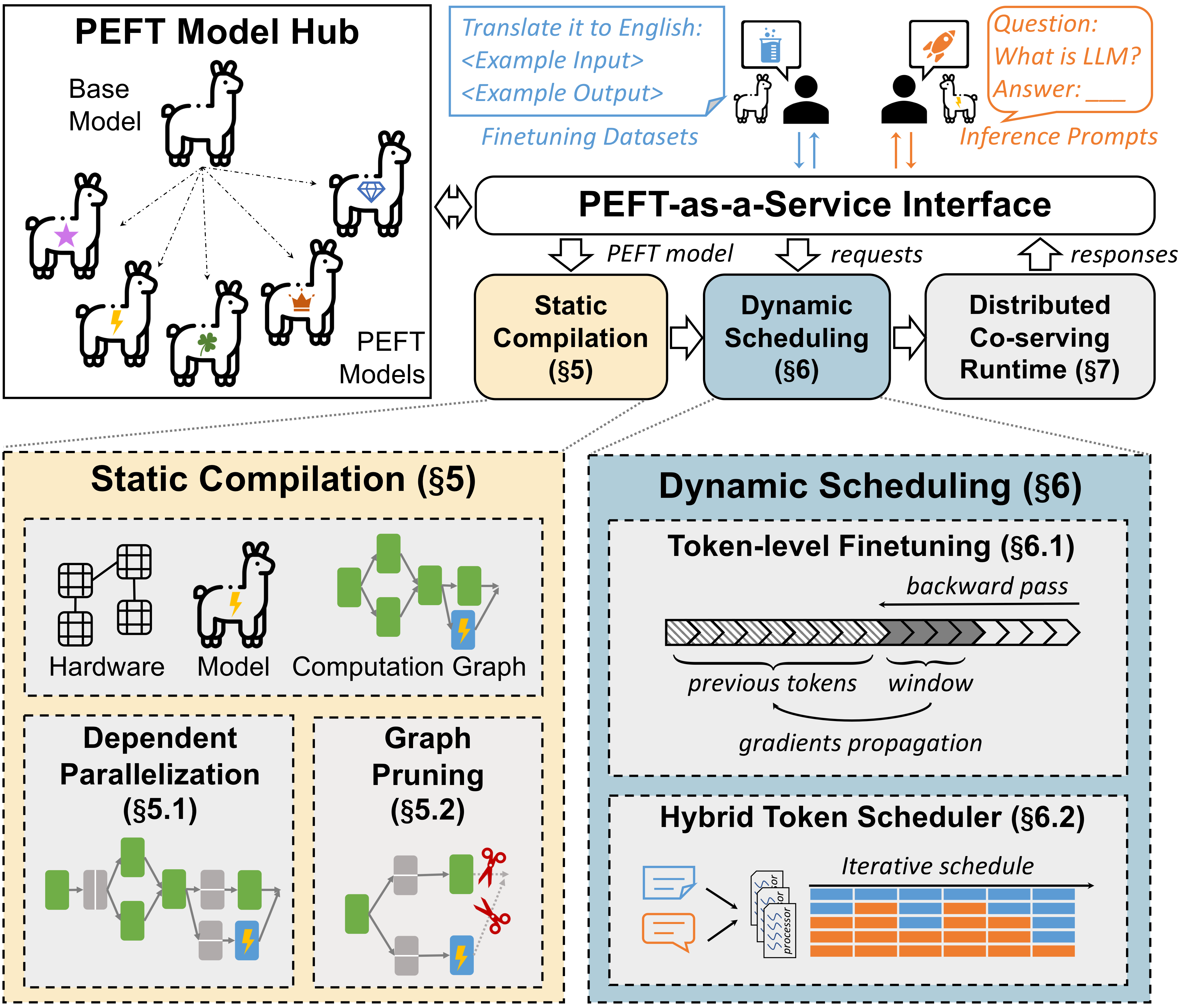
Co-Serving Architecture & PEFT-as-a-Service
FlexLLM introduces co-serving, a novel multiplexing technique that effectively handles bursty workloads while satisfying strict SLOs. The key insight is that inference and finetuning tasks, when using the same base LLMs, can be merged at fine granularity—at the level of individual tokens rather than entire requests or kernels.
The system provides a PEFT-as-a-Service (PaaS) interface that unifies inference and finetuning tasks, enabling their joint execution on shared GPU resources. FlexLLM represents a PEFT model as a sequence of bypass networks attached to the backbone LLM, where each bypass network takes a single tensor from the backbone LLM as input and produces a single output tensor that is added to one tensor of the backbone LLM. All existing PEFT methods can be represented in this format, enabling FlexLLM to fuse computation graphs of different PEFT models.
Static Compilation Optimizations
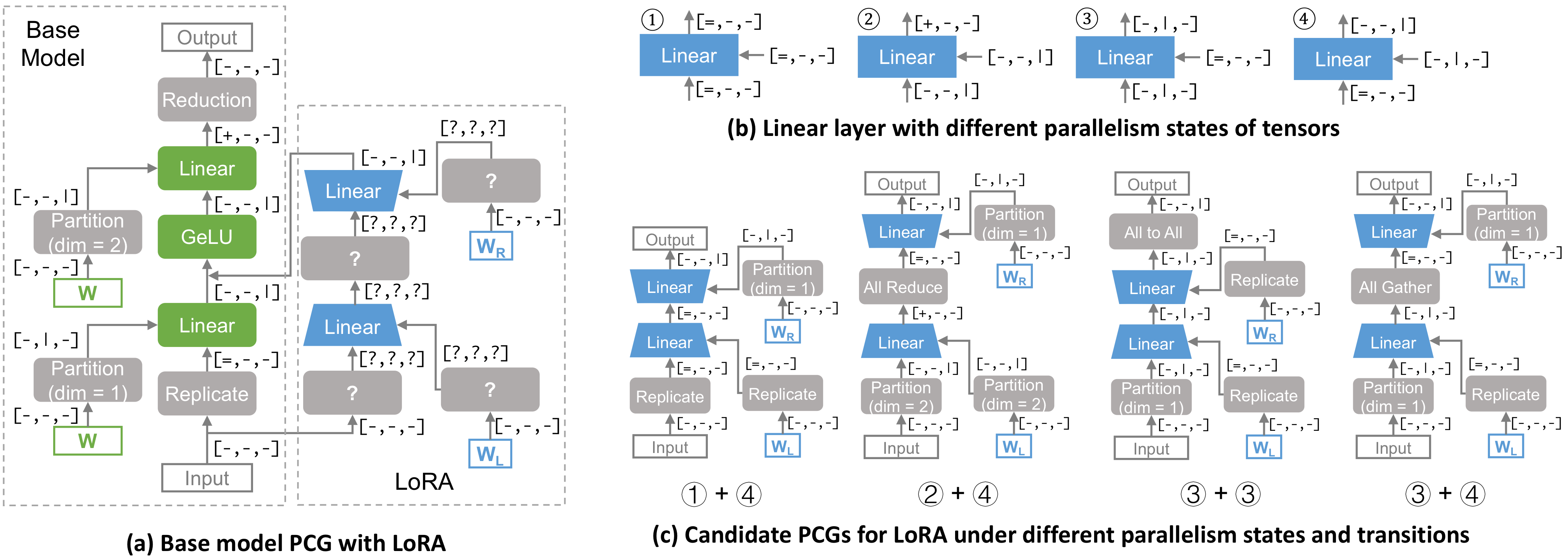
Dependent parallelization enables efficient distributed execution of PEFT models by creating parallel computation graphs that specify execution over distributed environments. The system uses four possible parallel states for tensor dimensions: non-parallel, partitioned, replicated, and pre-reduce.
Graph pruning optimizes memory usage by removing unnecessary tensors and operations from the computation graph. This optimization, combined with rematerialization and token-level finetuning, achieves up to 80% reduction in activation memory requirements compared to existing approaches.
Token-Level Finetuning & Hybrid Scheduling
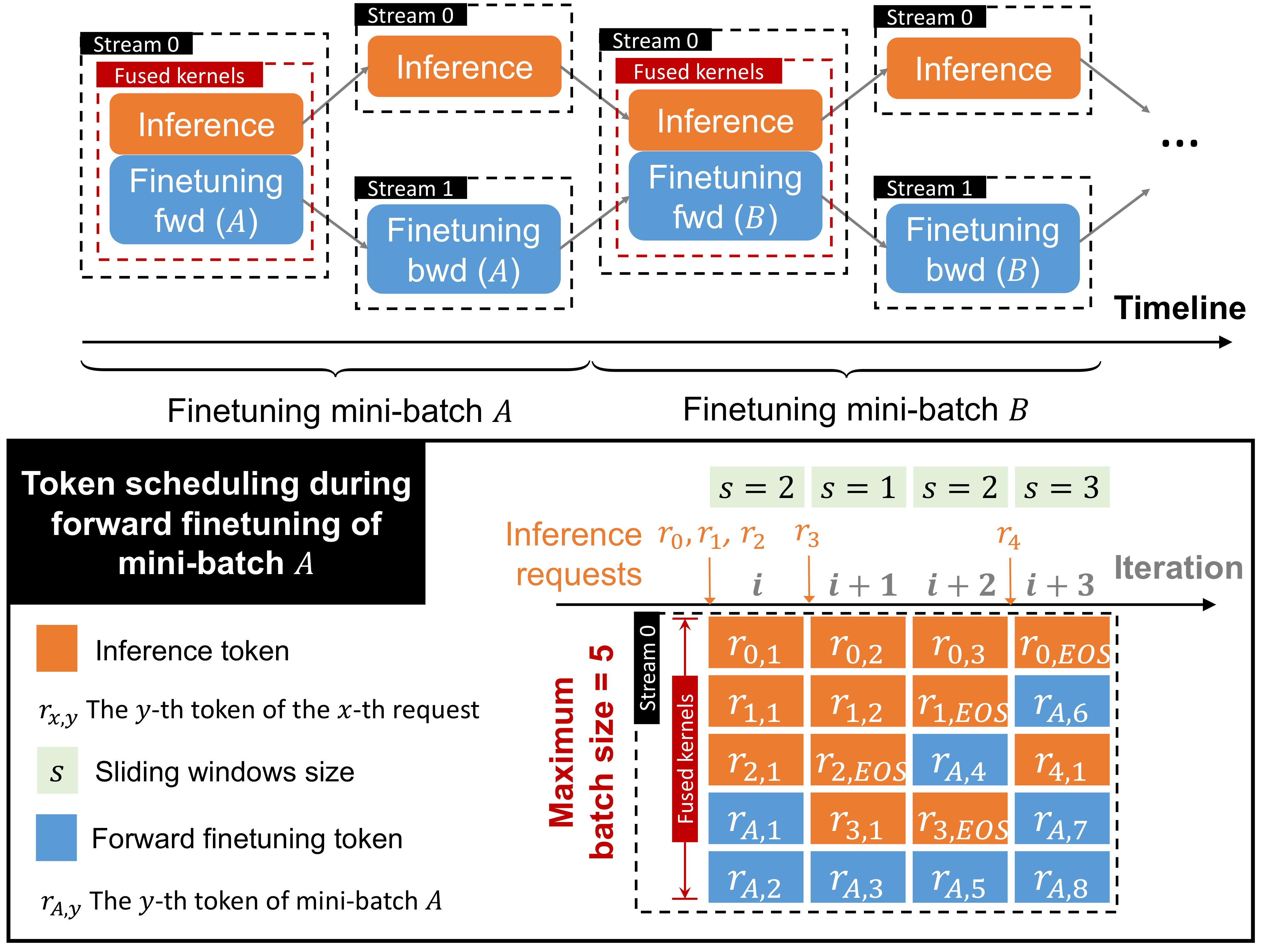
Token-level finetuning enables millisecond-scale resource reallocation in response to inference bursts. When inference requests suddenly spike, FlexLLM can instantly throttle finetuning tokens within the same GPU kernel execution, reallocating resources to maintain inference SLOs without context switching overhead.
The hybrid token scheduler dynamically interleaves inference and training tokens within each co-serving iteration. During normal load, finetuning tasks opportunistically consume idle capacity reserved for bursts, improving overall utilization while maintaining strict latency guarantees for inference requests.
Results
End-to-End Performance Comparison
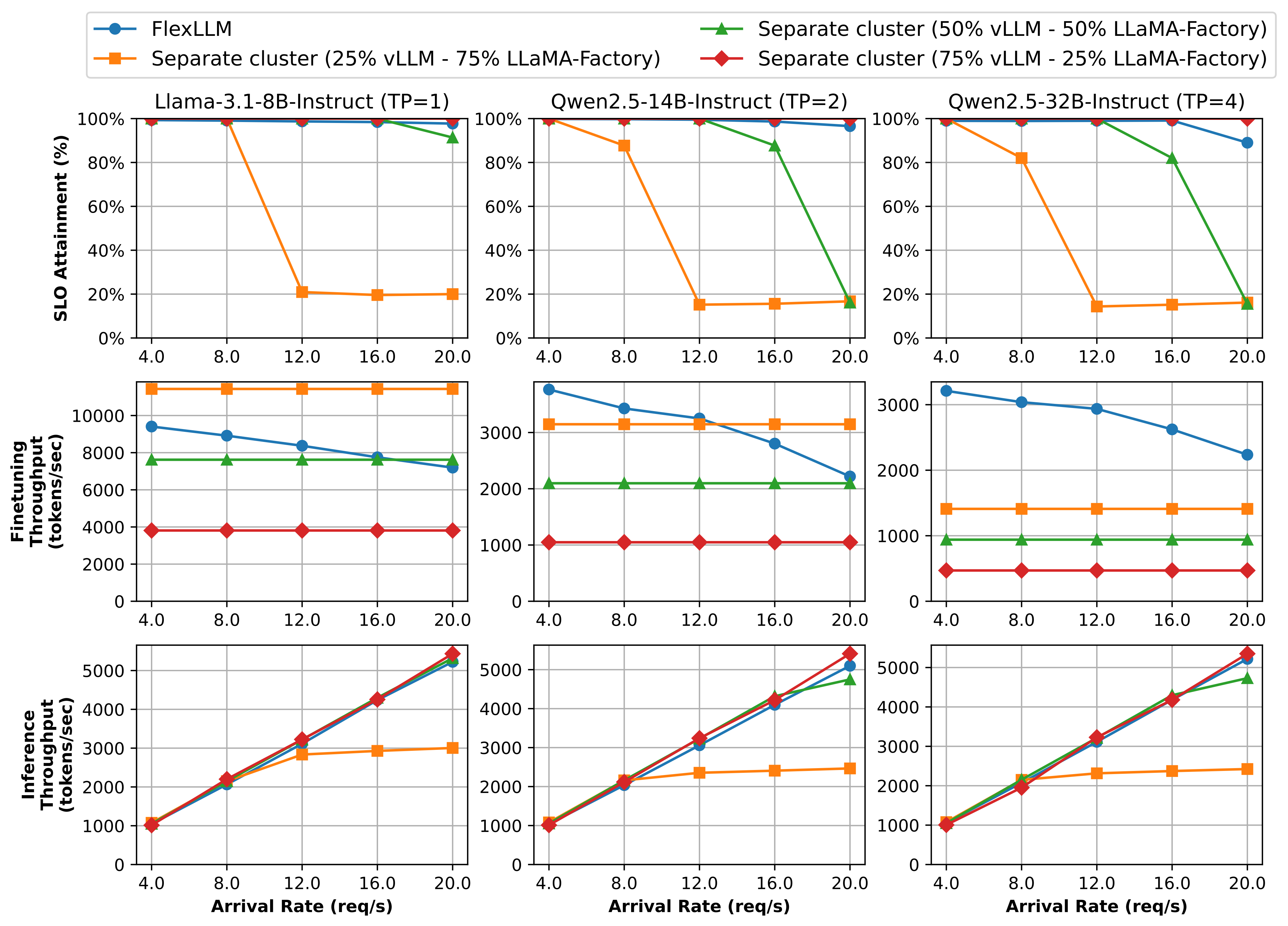
Performance comparison showing FlexLLM's co-serving approach compared to existing separate cluster approaches using vLLM for inference and LlamaFactory for finetuning. The separate approach uses different resource allocation strategies (25%-75% vLLM-LlamaFactory configurations).
Across all three models (LLaMA-3.1-8B, Qwen-2.5-14B, and Qwen-2.5-32B), FlexLLM matches the 75% vLLM - 25% LlamaFactory configuration in inference SLO attainment (at or above 90% even at 20 req/s) and inference throughput, while dramatically improving finetuning throughput.
Under heavy inference loads (20 req/s), FlexLLM sustains finetuning throughputs of 7.2K, 2.2K and 2.2K tokens/s for the three models respectively, compared to only 3.8K, 1.0K, and 0.5K tokens/s in the separate setup—achieving 1.9×-4.8× improvement. Under light inference loads (4.0 req/s), FlexLLM achieves 2.5×-6.8× improvement over the separate approach.
GPU Scheduling Comparison
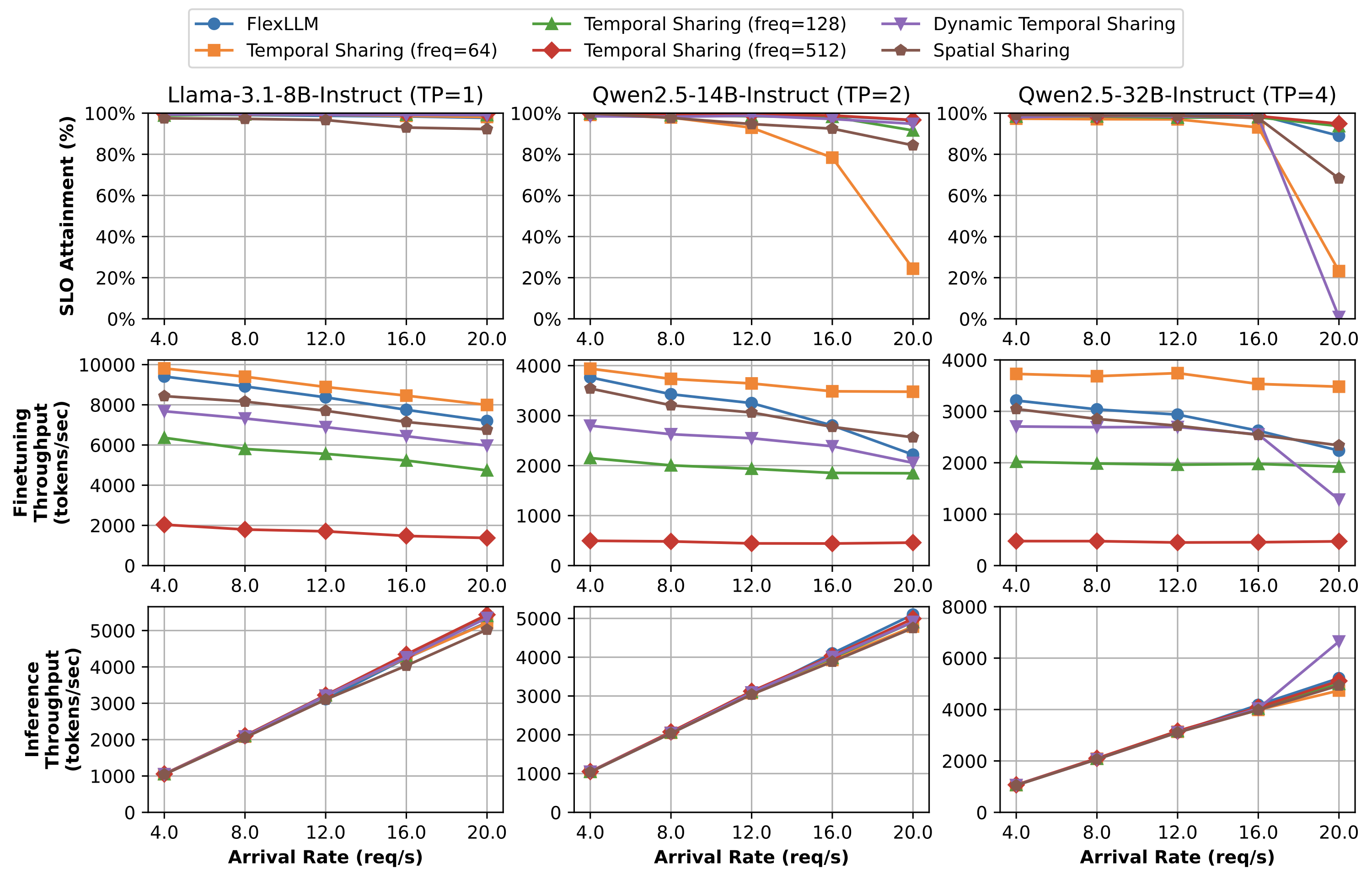
Comparison of co-serving with alternative GPU scheduling strategies: temporal sharing and spatial sharing. Temporal sharing interleaves inference and finetuning tasks over time, while spatial sharing simultaneously launches both using separate CUDA resources.
For temporal sharing, interleaving one inference iteration with one finetuning iteration violates SLOs for nearly all requests, as inference iterations complete in tens of milliseconds while finetuning takes several seconds. While low inference frequency (64) maximizes finetuning throughput, it adversely impacts SLO attainment. A frequency of 128 matches co-serving's inference metrics but reduces finetuning throughput by 0.57×-0.86× compared to co-serving.
Dynamic temporal sharing adapts based on queue lengths and arrival rates, maintaining SLO attainment above 90% in most scenarios with inference throughputs of 5.4K, 4.9K, and 6.6K tokens/s under heavy loads. However, co-serving's finetuning throughput is still 1.0–1.7× higher, and dynamic temporal sharing shows instability under the heaviest loads. Spatial sharing achieves comparable finetuning throughput but remains suboptimal in SLO attainment under heavy inference workloads due to interference between tasks.
Memory Optimization Effectiveness
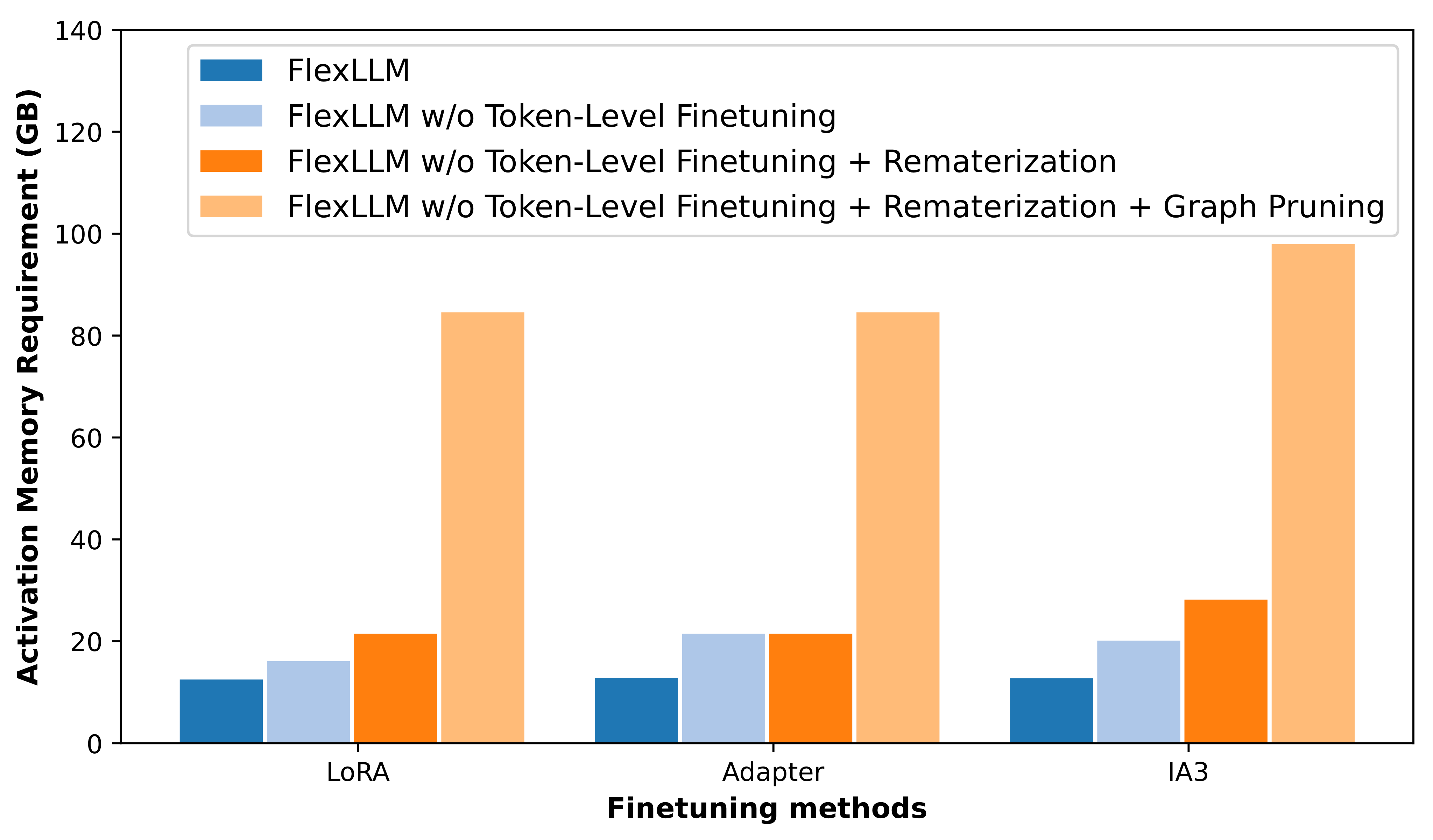
Ablation study of FlexLLM's memory optimizations showing activation memory requirements for different finetuning methods on a 70B LLM with sequence length 1024. FlexLLM saves 85%-87% memory requirements for activations compared to existing approaches.
The major improvement comes from graph pruning, which alone achieves 71%-74% activation memory overhead reduction. Rematerialization and token-level finetuning further reduce memory overhead by 0%-8% and 4%-10%, respectively. These optimizations enable FlexLLM to retain sufficient memory for inference requests' KV cache, ensuring eviction rates of 0% in most cases and peaking at only 1.2% for the largest model (Qwen2.5-32B) under the heaviest loads.
Dynamic Workload Adaptation
Case study demonstrating FlexLLM's ability to dynamically adapt to fluctuating inference workloads in real-time using a 10-minute interval of the BurstGPT trace with Qwen-2.5-14B model. Inference and finetuning requests are sampled from the ShareGPT and Sky-T1 datasets respectively.
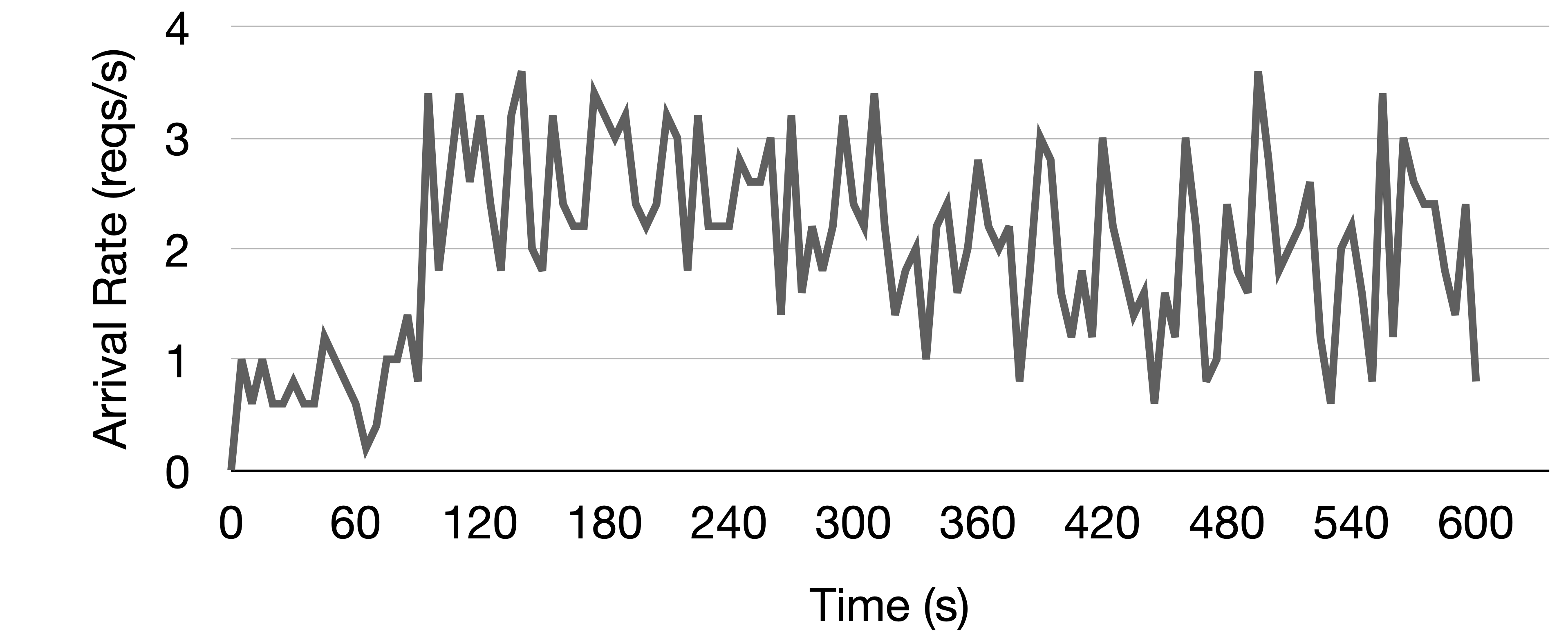
(Top) Inference request arrivals: The arrival rate initially increases to a peak level after around 90 seconds, then gradually decreases with some fluctuations, representing a realistic bursty workload pattern.
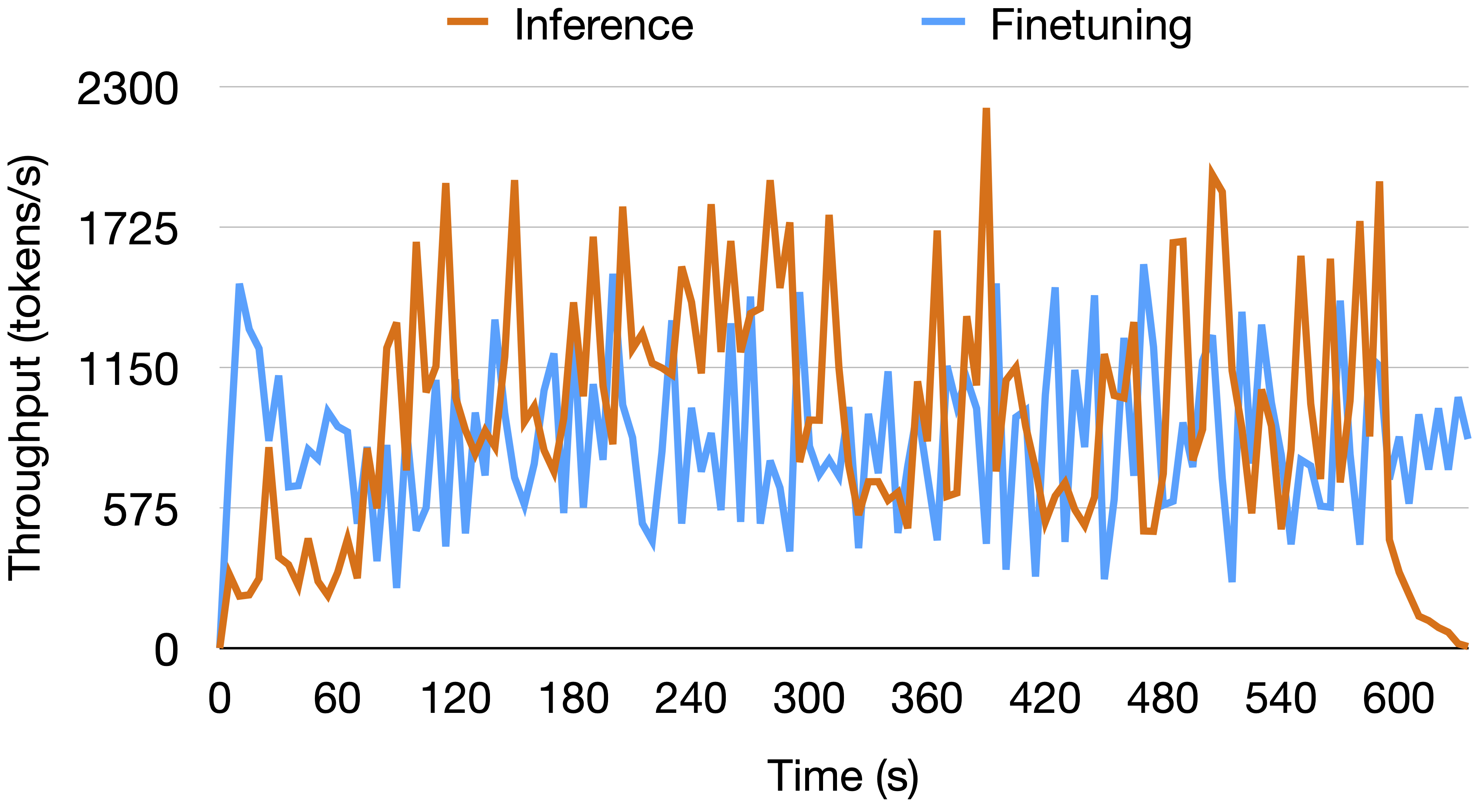
(Bottom) System throughput: FlexLLM automatically detects workload fluctuations and dynamically adjusts the ratio of inference tokens versus finetuning tokens in each iteration's batch. This adaptation significantly increases inference throughput from a few hundred to 2.25K tokens/s during peak demand while maintaining finetuning progress throughout the experiment.
BibTeX
@inproceedings{oliaro2026flexllm,
author = {Gabriele Oliaro and Xupeng Miao and Xinhao Cheng and Vineeth Kada and Mengdi Wu and Ruohan Gao and Yingyi Huang and Remi Delacourt and April Yang and Yingcheng Wang and Colin Unger and Zhihao Jia},
title = {FlexLLM: Token-Level Co-Serving of LLM Inference and Finetuning with SLO Guarantees},
booktitle = {The 23rd USENIX Symposium on Networked Systems Design and Implementation},
year = {2026},
url = {https://arxiv.org/abs/2402.18789},
arxiv = {2402.18789}
}